
Eric Cawi
A logical extension of the Distance Rings model is to fit a smooth function to the distribution of data found in ISRID. Examining the Euclidean Distance data for different categories, it was found that a lognormal curve roughly captured the shape of the data. The Log-Normal (LN) is a two parameter distribution which assumes that the logarithm of your data follows a normal distribution. The probability density function of the LN curve is given by, where are the mean and standard deviation of the logarithm of distance.

Using µ and σ for a particular category, a 1000x1000 distance array was created in numpy representing 50 meter cells for a total box size of 50km x 50km. Using the lognormal pdf in numpy the distribution was calculated for each cell. The central 500x500 entries in the array were used to form the 25km x 25 bounding box. To approximate the probability of being found outside the bounds, the sum of the inner array was divided by the sum of the total array and the result was saved as the probability inside the box. The central array is then saved in a png format, metadata for category, probability outside the box, and other desired information is added, and the picture is resized to 5001x5001 pixels. This size was not used originally because of memory/computational constraints.

One issue with the LN model is that the probability density function forces the probability to zero at the origin. In ISRID, about 10% of cases are found at or within 50 meters of the IPP, so when the model was scored about 10% of the cases scored extremely poorly. To compensate for this issue, the parameters were re-estimated conditional on not being found at the IPP and the distribution was generated based on those parameters. This had the general effect of spreading the probability further away from the central point. Additionally, for each category the probability of being found at the IPP was noted. A 50 m radius around the IPP was assigned this probability. To ensure that the probabilities added to 1, the LN portion was scaled by the total probability of being found outside of the IPP and the two arrays were combined. The result of this change is nearly identical to the previous map, but there is a bright spike at the center.

Thus far, conditional LN parameters have been computed for all of the cases present in the Mapscore database. As expected, the conditional LN (Lognormal2) improved the score of the regular LN (Lognormal) by roughly 10% for hikers, dementia, and child cases, so it was decided only to compute parameters for the conditional lognormal model. Additionally, this model significantly beats distance and performs similarly to the watershed/distance model, as can be seen from the confidence intervals below.
![]()
![]()

![]()
For searchers, this model suggests that if the subject is not found at the IPP there is a band of lower priority immediately surrounding the IPP. This means that the starting search radius can be increased once the IPP has been cleared. It also suggests that the probability of the subject being found far (e.g. greater than 5 or 6 kilometers out) drops quite significantly, so more effort should be concentrated closer to the IPP.
Comparison with Log-Cauchy:
The Log Cauchy (LC) is another long tailed distribution that features a probability spike at the origin and a secondary hump further out. Because this shape is similar to that of the conditional lognormal, it was decided to investigate how well the LC would fit the ISRID data. The probability density function of the LC takes the form, where µ and σ are the location and scale parameters of the Cauchy distribution of the natural logarithm of the distance. The parameters were estimated for the hiker, dementia, and child categories by taking the logarithm of the distance data from ISRID and using the median value for µ and half the inter-quartile range for σ. The figure below shows a comparison of the LC model to the conditional LN for the Hiker-else category. It should be noted that to preserve a good scale for the plot the values for the probability at the IPP are not shown for the conditional Lognormal Distribution. At the IPP in the conditional lognormal there is a large spike of probability in a small area, and plotting together with the LC would skew the scale and eliminate meaningful comparison.
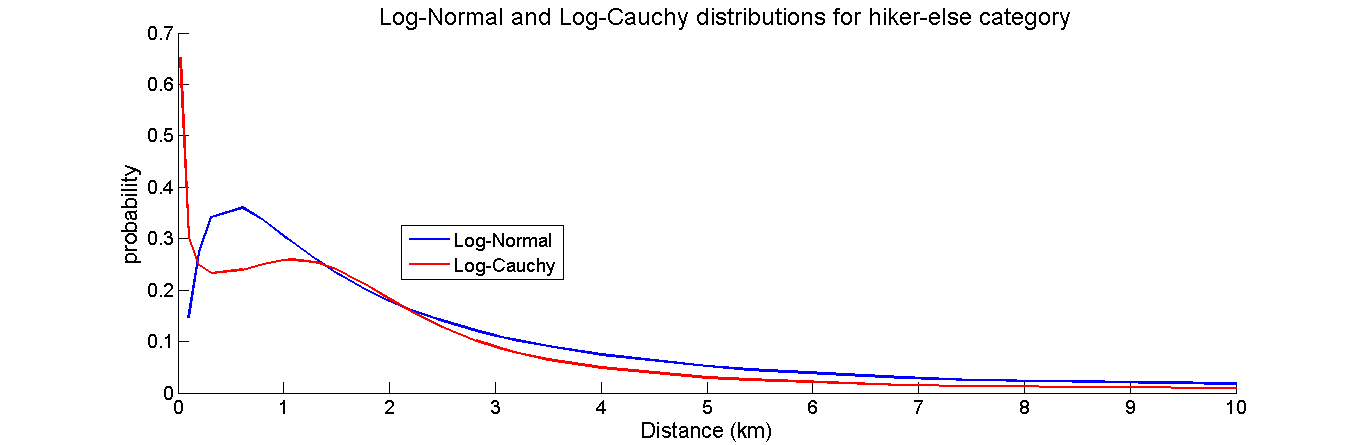
As this distribution has a high value near the origin, no spikes were added to compensate for the probability of finding the subject at the IPP. Instead, these cases were given a very small value to fall within the spike and avoid ln(0) errors in the calculations. To compare the two models category by category, a 10 by 10-fold cross validation was performed for each model. In each observation, the log likelihood was found by taking the natural logarithm of each distribution’s pdf evaluated at the validation set. For each fold the average log-likelihood was recorded, and the results of the ten folds were averaged. The difference between the log likelihoods of the LN and LC distributions was also calculated, and the results are shown below in a series of boxplots.
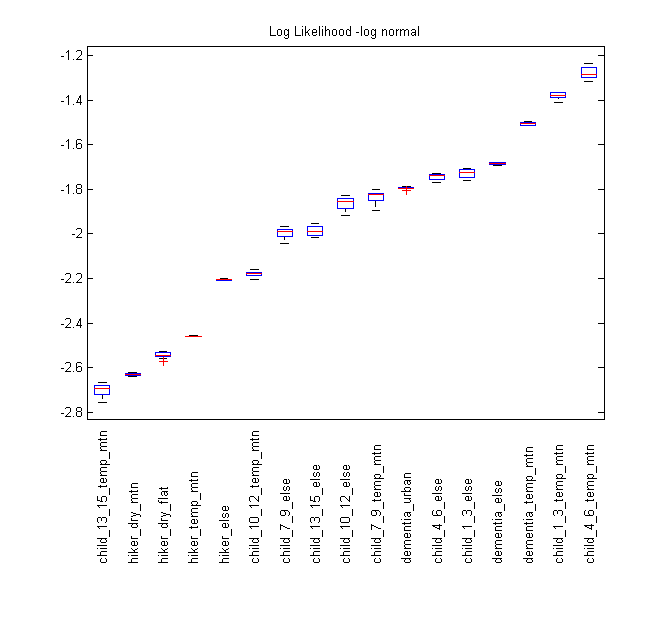
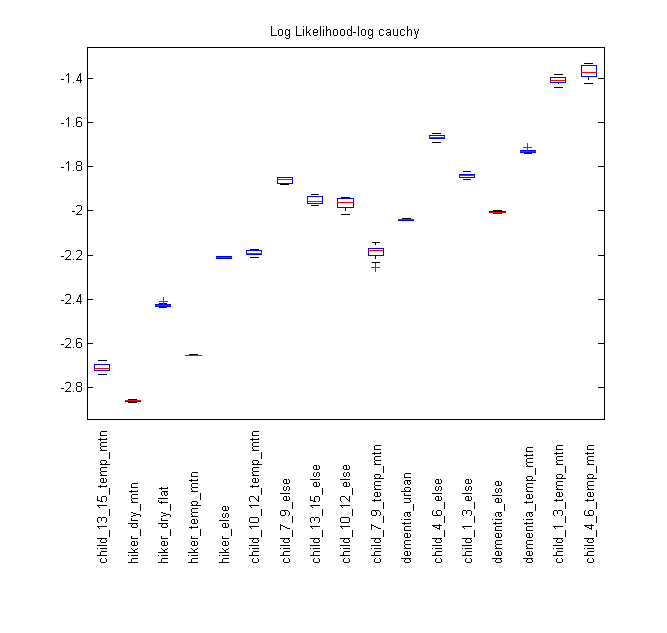
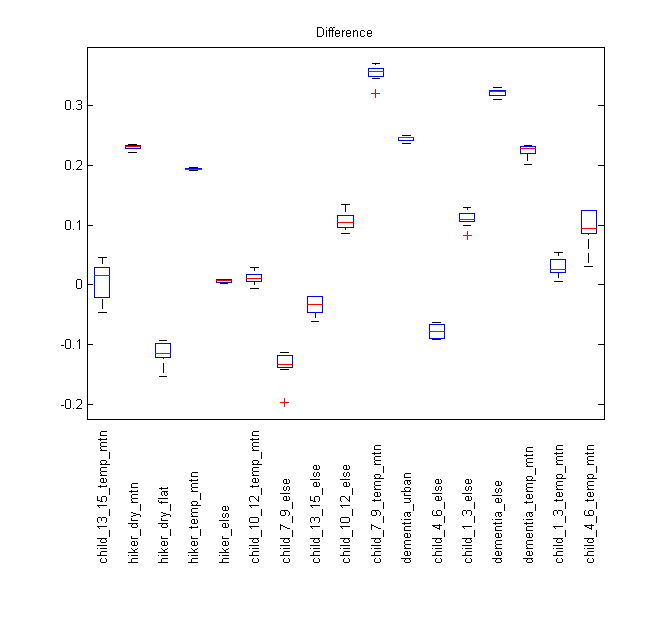
From the distance boxplot, it can be seen that the LN model is clearly better than the LC model for the majority of categories tested. LC beats LN in the hiker_dry_flat, child_13_15_else and child_4_6 else, and does slightly better in child_13_15_else. The child_13_15_temp_mtn, hiker_else, and child10_12_temp_mtn categories all show similar scores, and the rest of the categories fall in the LN model’s favor. For this reason, we have not created maps for the LC distribution on the basis that the scores would generally be similar or worse than the LN.
Overall, the child/dementia categories tended to score higher than hikers. This is possibly because children are much more likely to be found close to the IPP, and many dementia subjects’ motion tends to stop fairly quickly as they wander. Hikers also tend to go further if they feel that they can find help or know where they are going, leading to a larger average find distance from the IPP.
In the boxplots, several of the categories have very small spreads, signifying that the scores in each observation were the nearly the same in every run. Looking at the mean and standard deviations of the test set for each run, the results were also very similar, meaning that such similar scores are to be expected. Also, the low spread of scores seems to occur in the larger datasets, especially the “else” categories where most of the data was recorded. It should be noted that some of the ISRID categories had fewer than 20 entries with distance data, making the cross validation impossible as 10% of the training set was rounded down to one case, causing a zero variance answer.
In conclusion, there is no significant gain realized from fitting the distance data to a Log-Cauchy distribution over the conditional Log-Normal. However, the smooth LN was an improvement over distance and integration of the LN with models such as the combined Distance/Watershed or Distance/Linear Features may see a similar improvement. Other long tailed distributions such as the wakeby, Levy, or Burr distributions could also be compared to the LN, though parameter estimation may be more difficult for these distributions.
Eric is a senior in Engineering and Mathematics at George Mason. In 2014 he was nominated for a Goldwater scholarship. His work on MapScore won an Outstanding Project Award from the Volgenau School of Engineering student project competition. He is planning to use his mapping work in a collaborative Senior Design project involving small UAVs for WiSAR.
Does the data fit using the cond Log-Normal curve include made at the IPP?
Don, thanks for the note, and good question. No, the model is a proper mixture of Dist for IPP + Dist conditional on not-IPP. Dist for IPP is defined as uniform probability from 0-25m, for the ~8% of cases found in that range. The lognormal is fit to the other ~92%. The proportions vary by category.